

ШЕНЖЕН – Големият моделен екип на Tencent Hunyuan официално пусна HunyuanOCR с отворен код, специализиран лек визуален езиков модел за оптично разпознаване на символи (OCR), съдържащ само 1 милиард параметъра.
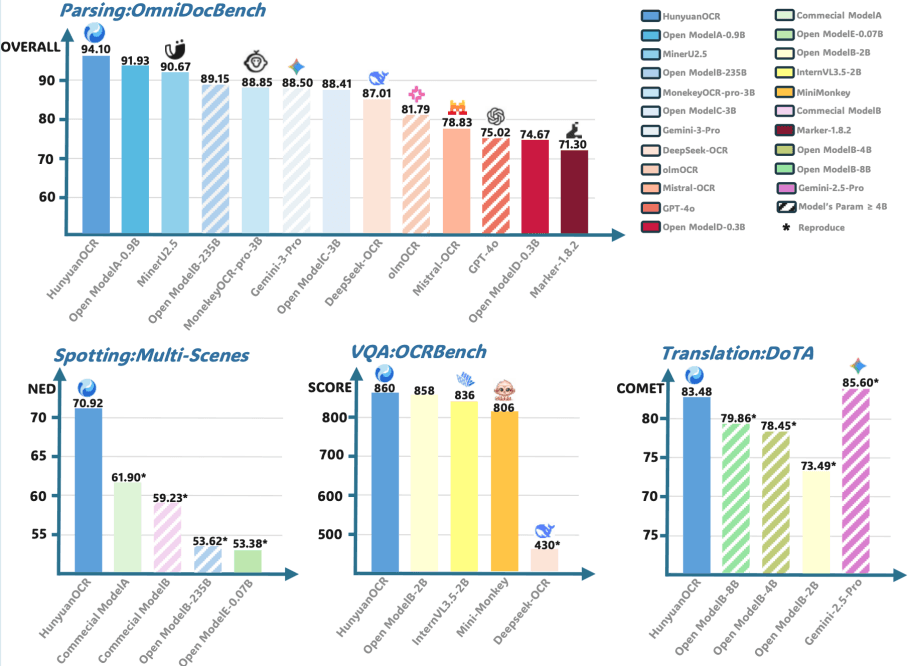
Моделът съчетава естествена архитектура на Vision Transformer (ViT) с олекотен голям езиков модел (LLM), осигурявайки производителност на комерсиално ниво при откриване на текст, парсиране на документи и извличане на информация. Наскоро той спечели първо място в пистата за малки модели на предизвикателството ICDAR 2025 DIMT и постигна най-съвременни резултати в бенчмарка OCRBench за модели под параметри 3B.
HunyuanOCR въвежда три ключови пробива:
- Унифицирана възможност за многозадачност – поддържаща разпознаване на текст, сложен анализ на оформлението, извличане на информация в отворено поле и превод на изображения в рамките на една ефективна рамка
- Архитектура от край до край – елиминиране на традиционните тръбопроводи за предварителна обработка и намаляване на натрупването на грешки
- Оптимизация на обучението за подсилване – демонстриране, че RL може значително да подобри производителността при множество OCR задачи
Моделът спечели бързо привличане на общността, класирайки се сред четирите най-популярни модела в Hugging Face и получи над 700 звезди в GitHub за кратък период от време. Той също така е интегриран в машината за изводи на vLLM.
Предлага се сега на Hugging Face и ModelScope, HunyuanOCR предоставя на изследователите и разработчиците мощно, внедряемо OCR решение, което балансира висока точност с изчислителна ефективност – особено ценно за крайно внедряване и индустриални приложения.
Source link
Like this:
Like Loading…
Нашия източник е Българо-Китайска Търговско-промишлена палaта